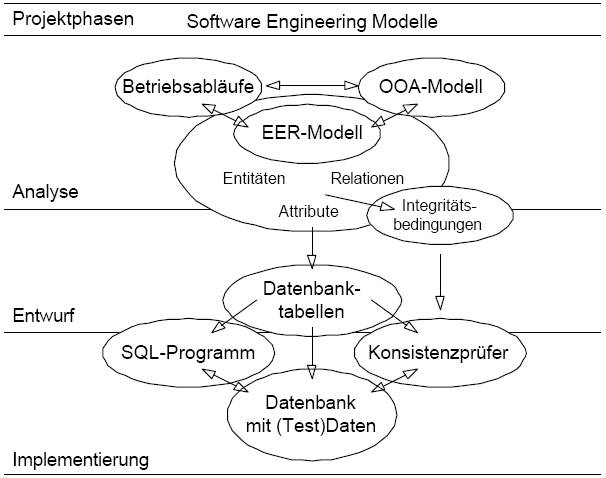
Für die Entwicklung von großen kommerziellen Projekten
ist ein ausgefeiltes EER-Modell von grundlegender Bedeutung, da ein
ineffizienter Ansatz für die Problemlösung hier besonders gut und frühzeitig
erkannt werden kann. Ist eine geeignete Lösung gefunden, so ist durch das
EER-Diagramm eine übersichtliche Beschreibung des gesamten
Projektdatenbestandes gegeben, der auch von Personen, die nicht unmittelbar bei
der Entwicklung beteiligt waren, einfach überblickt werden kann. Weiters
erleichtert die einfache Notation die Kommunikation mit 'Nicht-Technikern' wie
Managern oder inhaltlichen Ansprechpartnern.
Zu Beginn der Analyse kann ein grobes EER bei der
Bestimmung der Komplexität des Systems hilfreich sein – die Anzahl der Tabellen
hängt mit der Anzahl der Objekte und Dialoge zusammen – und damit als Basis für
eine erste grobe Aufwandschätzung dienen.
Das Konzept des EER-Diagramms stützt sich auf eine
genaue, der Problemstellung entsprechenden Beschreibung der Aufgabe durch
Entitäten und Beziehungen. Wenn diese ungünstig gewählt werden, kann eine
umfangreiche Neuentwicklung des Projektes notwendig sein. Dies verursacht einen
bedeutenden Aufwand an Zeit und Kosten.
Weiters ist zu bedenken, dass erfasste Daten meist
bedeutend langlebiger als die zugehörigen Programmteile sind. Denn selbst dann,
wenn ein Unternehmen seine komplette Software auf ein anderes System portiert,
trachtet der kluge Entwickler danach, den bisherigen Datenbestand nicht einfach
aufgeben zu müssen. Er konvertiert ihn zwar in ein anderes Datenbankformat,
versucht allerdings gleichzeitig, die Dateistruktur, die durch das EER‑Diagramm
vorgegeben ist, beizubehalten. Bei großen Datenmengen würde eine manuelle
Überprüfung oder gar komplette Neuerfassung der Daten einen untragbaren
Arbeits- und Zeitaufwand bedeuten.
Ein schwaches Datenbankkonzept führt mit der Zeit
typischerweise zur 'Erosion' der Konsistenz der Daten. Konsistente Daten sind
Basis für einen sinnvollen Programmtest; sonst entsteht leicht ein
Teufelskreis: Falsche Daten stören das Programm, das gestörte Programm wiederum
verwurstet Daten.
Ein EER-Modell ist
ein abstraktes Modell der Daten der realen Welt eines Aufgabengebietes oder
Systems.
Es wird für
- die
Datenmodellierung in Analysephase
- den
Datenbankentwurf in Designphase
verwendet
Die wesentlichen Begriffe sind:
- Objekte,
Beziehungen
- Entity,
Relationship, Attribute
- Relationenmodell
- Integritätsbedingungen

- Beziehungen
- Peter
besitzt einen Ford
- Susi
besitzt einen Mazda und einen Ford
- Toni
ist mit Anna verheiratet
- Lisa
ist Lehrerin von Peter
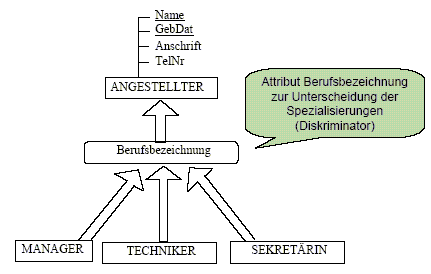
Entitäten,
Attribute und Relationen (bzw. Beziehungen) sind die drei Grundbausteine in
jedem EER-Diagramm. Entitäten sind problemspezifische Objekte und werden
grundsätzlich realen Personen, Orten, Dingen oder Vorkommnissen zugeordnet. Die
Eigenschaften einer Entität werden durch typisierte Attribute bzw. durch deren
Werte beschrieben. Ein Attribut oder mehrere Attribute gemeinsam bilden
den Primärschlüssel der Entität, der diese Entität eindeutig identifiziert. Beziehungen
repräsentieren Zusammenhänge zwischen den Entitäten und kommen
Assoziationen gleich.
Abb. Entität
‘Student’ mit Attributen: MatNr, Name, Geburtsdatum; ‘Person’ mit
Name,
Geburtsdatum, Adresse
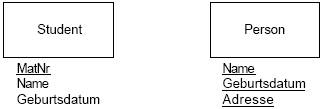
Das Attribut
MatNr (Matrikelnummer) ist Primärschlüssel für die Entität Student und wird zur
Unterscheidung von Attributen, die nicht zum Primärschlüssel gehören,
unterstrichen dargestellt. Wenn kein Attribut alleine einen Primärschlüssel
bilden kann, können auch zwei oder mehr Attribute gemeinsam den Primärschlüssel
bilden.
Entität. Eine
Entität ist eine persistente (d.h. dauerhaft gespeicherte) Klasse, die Objekte
enthält, die mit Objekten anderer Entitäten in Beziehung stehen können. Stammdaten
sind langlebige Entitäten, die die statische Grundstruktur der Daten einer
Anwendung abbilden, Journaldaten bilden die laufenden Transaktionen ab,
die Stammdaten betreffen (etwa Verkauf). Eine Entität wird üblicherweise mit
einem Substantiv (Hauptwort) in der Einzahl benannt (z.B. Kunde, nicht Kunden).
Attribut. Jede
Entität besitzt mehrere Attribute, deren Werte jeweils ein Objekt der Entität
beschreiben. Ein Attribut speichert ähnlich einer Variable Informationen
innerhalb einer Entität. Jedes Attribut hat einen eindeutigen Typ und einen
gültigen Wertebereich.
Ein Entity ist eine Klasse
von Objekten, aber nur Daten und keine Methoden

- Der eindeutige Schlüssel (Primärschlüssel) wird
unterstrichen
- Der eindeutige Schlüssel identifiziert eindeutig
die Objekte des Entity
Relation. Der
Begriff Relation hat je nach aktuellem Kontext eine von zwei Bedeutungen: In
einem EER-Diagramm ist eine Relation die Beziehung zwischen zwei Entitäten; im
Bereich Datenbanktabellen ist eine Relation ein Tupel von Attributen, das eine
Entität oder m:n-Beziehung beschreibt.
Schlüssel. Attribute,
die ausreichen jedes Objekt einer Entität eindeutig zu beschreiben,
werden als Schlüssel bezeichnet (z.B.
Sozialversicherungsnummer). Ein zusammengesetzter Schlüssel besteht aus
mehreren Attributen.
Ein Primärschlüssel ist ein möglichst kurzer
(minimaler) Schlüssel, der in der Datenbank zur Identifizierung einer Entität
verwendet wird.
Ein Fremdschlüssel ist ein Attribut, das
Schlüssel in einer benachbarten Entität ist und damit die beiden Entitäten
miteinander in Relation setzt.
Eine schwache Entität hat keinen eigenen
Primärschlüssel und bildet diesen daher mit Hilfe von Fremdschlüsseln von
benachbarten starken Entitäten.
Integrität(sbedingung). Integritäts- oder auch Konsistenzbedingungen sind logische
und widerspruchsfreie Bedingungen, denen Attribute und Entitäten in einer
konsistenten, d.h. logisch richtigen und sinnvollen, Datenbank genügen müssen.
Eine konsistente Datenbank ist im Algemeinen die Grundlage für das
Funktionieren jedes Programms, das mit den Daten der Datenbank arbeiten soll.
Ein Konsistenzprüfer ist ein Programm, das die Konsistenzbedingungen
einer gegebenen Datenbank überprüft und etwaige Inkonsistenzen geeignet meldet.
Relationales Datenbanksystem. Ist eine Datenbankstruktur, zwischen deren Tabellen
Beziehungen (Relationen) bestehen, die durch ein EER-Diagramm veranschaulicht
werden können. Der Großteil der heute kommerziell verwendeten Datenbanken sind
relationale Datenbanken. Ihre Vorteile liegen in der höheren Modularität und
der besseren Performance gegenüber klassischen (hierarchischen) Datenbanken.
Tabelle. Ist
eine Datei des Datenbanksystems. Sie entspricht einer Tabelle mit den
Attributnamen in der Kopfzeile und deren Werten in den Spalten darunter. Eine
Zeile einer Tabelle nennt man auch Tupel. Meist wird über das
Schlüsselattribut der Tabelle ein Index gelegt, um die Geschwindigkeit
der Suche nach einem Datensatz der Tabelle zu erhöhen.
Index. Ist
eine Hilfstabelle, die der Datenbank das schnellere Auffinden eines bestimmten
Datensatzes ermöglicht. Der schnellere Suchzugriff wird mit erhöhtem
Platzbedarf bezahlt; beim Einfügen von Daten benötigt das Aktualisieren der
Indextabellen extra Zeit.
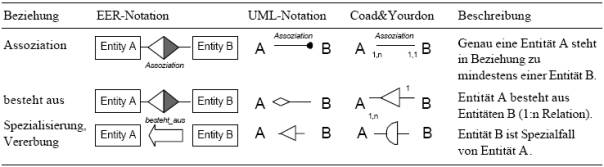
In der folgenden Abbildung ist der Vergleich von drei
verbreiteten Notationen für statische Zusammenhänge zwischen Entitäten bzw.
Objektklassen zu sehen. Bemerkenswert sind einerseits gleiche Zeichen, wie etwa
das Dreieck, das in UML Vererbung und in Coad & Yourdon
Ganzes-Teil-Beziehung bedeutet. Andererseits ist das Anschreiben der
Vielfachheiten von Assoziationen bei UML und Coad & Yourdon genau
gegengleich. Beim Lesen von Diagrammen sollten Sie daher zu allererst darauf
achten, die aktuell gebräuchliche Notation herauszufinden, um die richtige
Interpretation sicherzustellen.
Vergleich unterschiedlicher
Notationen
Zum EER-Modell sind Integritätsbedingungen für
Entitäten, Attribute und Relationen extra anzugeben oder können aus dem Modell
abgeleitet werden. Diese Integritätsbedingungen können in Form eines
automatischen Konsistenzprüfers zur Laufzeit den Inhalt der Datenbank auf
Inkonsistenzen überprüfen helfen.
Aus einem EER-Diagramm kann in der Entwurfsphase
relativ einfach eine relationale Datenbankstruktur in Tabellenform abgeleitet
werden. Mit Hilfe von SQL-Anweisungen kann anhand dieser Datenbanktabellen eine
Datenbank angelegt, mit Daten befüllt und anschließend für Auswertungen
abgefragt werden.
Vorbedingung: Anforderungen
an das System und typische Szenarien der Verwendung des zukünftigen Systems
sind bekannt bzw. ausreichend klar beschrieben.
Schritte:
Entitäten finden; Relationen zwischen den Entitäten
beschreiben; Attribute zu Entitäten und Relationen finden;
Integritätsbedingungen definieren.
Check:
Anhand der Anforderungen bzw. von typischen Szenarien
überprüfen, ob mit dem bisher beschriebenen Modell alle wesentlichen Normal-,
Sonder- und Fehlerfälle abgedeckt sind. Gegebenenfalls das Modell anpassen oder
verfeinern. Auf klare Verwendung von Begriffen achten. Redundanzen und unnötige
Komplexität vermeiden.
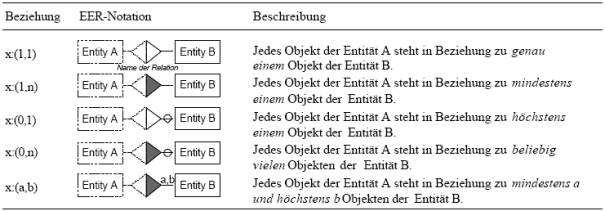

Jeder Projektleiter leitet (genau) ein Projekt.
Jedes Projekt wird von (genau) einem Projektleiter geleitet.

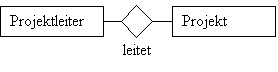
Jeder Lehrer ist einer Abteilung zugeordnet.
Jede Abteilung besitzt mindestens einen (oder mehrere)
zugeordnete Lehrer.


Jeder Schüler lernt mehrere Unterrichtsgegenstände.
Jeder Unterrichtsgegenstand wird von mindestens einem
Schüler gelernt.


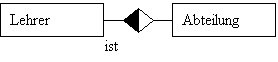
optionale Relationships
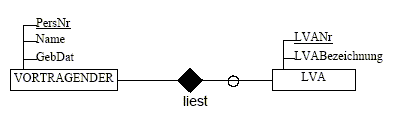
Jeder Vortragender liest keine, eine oder mehrere
Lehrveranstaltungen (LVA). Jede Lehrveranstaltung wird von mindestens einem
Vortragenden gelesen.
Für jeden Studenten und jede seiner inskribierten
Studienrichtungen soll das Semester der Erstinskription bekannt sein.
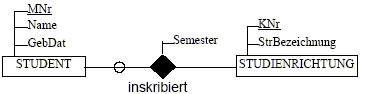
Jeder Student inskribiert zumindest eine Studienrichtung.
Eine Studienrichtung ist von keinem oder mehreren Studenten
inskribiert.
- Zeugnis
ist ein schwaches Entity (doppelter Rahmen)
- Eindeutiger
Schlüssel von Zeugnis wäre (MNr, LVANr, Datum)
- Es
braucht für seinen Schlüssel Attribute von anderen Entities
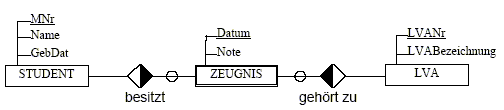
Jede m:n Relationship kann in zwei 1:n Relationships zerlegt
werden
Beispiel:
Die m:n Relationship
Kann zerlegt werden in

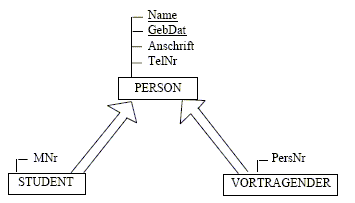
- STUDENT
und VORTRAGENDER sind Spezialfälle einer PERSON
- Jeder
Student und jeder Vortragende ist eine Person, sie erben daher alle
Attribute von Person
- Die
gleiche Person kann zugleich Student und Vortragender sein
sind Relationships, die durch andere Relationships
ausgedrückt werden können
redundante Relationships können inkonsistent werden
redundante Relationships sollten eliminiert werden
Beispiel:
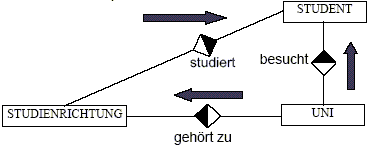
Die Relation „besucht“
kann durch „studiert“ und „gehört zu“ ausgedrückt werden.
Vorbedingung:
Es gibt ein ausgereiftes EER-Modell.
Schritte:
Entitäten, Relationen und Integritätsbedingungen auf
Datenbanktabellen abbilden. Für die Attribute Typen, Wertebereiche und Integritätsbedingungen
bestimmen. Performanceüberlegungen; Trade-off zwischen Zeitaufwand und
Platzbedarf. SQL-Pseudocode für Abfragen und Auswertungen.
Check:
Sind via SQL die wesentlichen Abfragen und
Auswertungen für Betriebsabläufe und Anwendungsszenarien möglich?
Das Relationenmodell wird aus
dem EER Modell abgeleitet
Jedes
Entity wird durch eine n-stellige Relation beschrieben
Beispiel:
Entity
Vortragender:
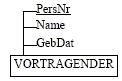
Relation:
VORTRAGENDER (PersNr, Name, GebDat)
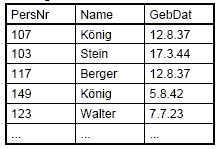
Darstellung
möglicher Inhalte in einer Tabelle:
Regel:
Der
Schlüssel von einem der beiden Entities wird zusätzliches Attribut des anderen
Entities (als Fremdschlüssel)
Beispiel:
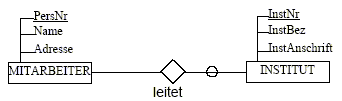
Jeder
Mitarbeiter leitet höchstens ein Institut
Jedes
Institut wird von genau einem Mitarbeiter geleitet
Relationen:
MITARBEITER
(PersNr, Name, Adresse)
INSTITUT
(InstNr, InstBez, InstAnschrift, PersNr)
Regel:
Der
Schlüssel desjenigen Entities, das in der Relationship bei 1 auftritt, wird als
zusätzliches Attribut zum Entity auf Seite n hinzugefügt
Beispiel:

Jeder
Mitarbeiter ist genau einem Institut zugeordnet
Jedem
Institut ist zumindest ein Mitarbeiter zugeordnet
Relationen:
MITARBEITER
(PersNr, Name, Adresse, InstNr)
INSTITUT
(InstNr, InstBez, InstAnschrift)
Regel:
Jede
m:n Relationship wird zu einer eigenen Relation. Der Schlüssel dieser
Relationen ist aus den Schlüsseln der beiden beteiligten Entities zusammengesetzt.
Beispiel:
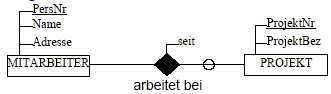
Jeder
Mitarbeiter arbeitet bei keinem oder mehreren Projekten
Bei
jedem Projekt arbeitet mindestens ein Mitarbeiter
Relationen:
MITARBEITER
(PersNr, Name, Adresse)
PROJEKT
(ProjektNr, ProjektBez)
ARBEITET_BEI
(ProjektNr, PersNr, seit)
Tabellendarstellung:

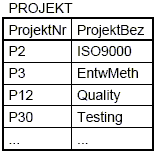
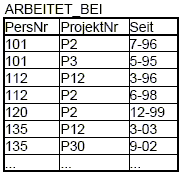
Regel:
Die
spezialisierten Entities erben den Schlüssel des allgemeinen Entities.
Beispiel:
Relationen:
PERSON
(Name, GebDat, Anschrift, TelNr)
STUDENT
(Name, GebDat, MNr)
VORTRAGENDER
(Name, GebDat, PersNr)
Bedingungen für die
Konsistenz der Datenwerte. Integritätsbedingungen sind wichtig für die
Implementierung, Tests und Wartung.
Jeder
Wert eines Fremdschlüssels muss in der Relation, in der er Primärschlüssel ist,
als Wert enthalten sein.
Beispiel:
Ist
HSNr ein Fremdschlüssel in der Relation
LVA (LVANr, LVABez, HSNr)
Da
HSNr Primärschlüssel in
HÖRSAAL (HSNr, Plätze, Ort)
ist.
Beispiele:
1
≤ PersNr ≤ 10 000
1
≤ Monat ≤ 12
Gewinn
≥ 0
Beispiele:
Landezeit
≥ Startzeit
Soll
+ Haben = 0
Rechnungsdatum
≤ Zahlungsdatum
∑
aller belegten Tennisplätze ≤ maximale Anzahl an Plätzen
Normalformen helfen
Redundanzen und Inkosistenzen zu vermeiden.
jedes Attribut hat höchstens
einen Wert
Beispiel:
Hat das Attribut Name den
Inhalt „Herr Mag. Walter Huber“, so sind darin mehrere Werte enthalten: Anrede,
Titel, Vorname und Nachname.
Nach 1. Normalform muss
dieses Attribut in 4 Attribute aufgelöst werden:
|
Attribut
|
Wert
|
|
Anrede
|
Herr
|
|
Titel
|
Mag.
|
|
Vorname
|
Walter
|
|
Nachname
|
Huber
|
1. Normalform + alle
Attribute sind vom gesamten Primärschlüssel, aber nicht von Teilschlüsseln
funktional abhängig.
Beispiel:
Schüler-Lehrer (SchülerNr,
LehrerNr, S-Name, L-Name, GegenstandNr)
Problem: die Attribute S-Name
(Name des Schülers) und L-Name (Name des Lehrers) sind nicht vom gesamten
Primärschlüssel abhängig.
Lösung:
Lehrer (LehrerNr,
L-Name)
Schüler (SchülerNr,
S-Name)
Schüler-Lehrer (SchülerNr,
LehrerNr, GegenstandNr)
2. Normalform + alle
Attribute sind nur vom gesamten Primärschlüssel, aber nicht von Teilschlüsseln
oder anderen Attributen funktional abhängig (außer von Schlüsselkandidaten).
Beispiel:
Schüler-Lehrer (SchülerNr,
LehrerNr, GegenstandNr, Gegenstand-Bez)
Problem: die Bezeichnung des
Gegenstandes ist zwar eindeutig durch die Kombination von SchülerNr und
LehrerNr definiert aber eigentlich abhängig von der GegenstandNr.
Lösung:
Gegenstand-Bez in dieser
Relation streichen, dafür folgende Relation schaffen:
Gegenstand (GegenstandNr,
GegenstandBez)
In der Praxis der Datenmodellierung sollte spätestens
am Ende das Ergebnis auf folgende Punkte überprüft werden:
Begriffe. Alle
verwendeten Begriffe sind klar und eindeutig; Namen werden nur einmal
vergeben.
Entitäten. Gibt
es Entitäten, die nicht gut geeignet sind (es gibt etwa nur eine Instanz, die
Daten sind schlecht strukturiert, es gibt kein oder nur ein Attribut). Name der
Entität muss in Einzahl formuliert sein.
Attribute. Alle
Attribute sind klar Entitäten zuordenbar; alle Schlüssel sind eindeutig, bei
den Attributen im EER-Diagramm sind keine Fremdschlüssel angegeben.
Notation. Die
EER-Notation ist in allen wesentlichen Punkten eingehalten.
Vollständigkeit. Alle wesentlichen Betriebsabläufe und Auswertungen sind mit den Daten
des EER durchführbar.
Um das Verständnis zu vertiefen und auch um einigen
oft gemachten Fehlern vorzubeugen, werden hier einige Beispiele von falschen
und anschließend korrigierten EER-Diagrammen behandelt.
Zu viele Attribute. Einer der am häufigsten gemachten Fehler bei der Erstellung eines EER‑Diagramms
ist, dass oft zu viele Attribute in eine Entität gepackt werden. Grundsätzlich
ist zu hinterfragen, ob Attribute, die einer Entität zugeordnet sind, eigentlich
schon eine eigene Entität beschreiben.
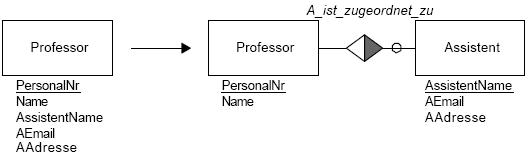
Beispiel: Hier wurden der Entität Professor die
zusätzlichen Attribute zur Beschreibung seines Assistenten mitgegeben (dadurch
ergibt sich implizit eine unerwünschte 1:1-Relation von Professor und
Assistent). Da sich allerdings ‘AEmail’ und ‘AAdresse’ nur auf ‘AssistentName’ beziehen,
kann eine eigene Entität Assistent generiert werden. Will man verdeutlichen, dass
ein Professor keinen, einen oder mehrere Assistenten haben kann und ein
Assistent zu genau einem Professor gehört, so wird dies durch eine optionale
1:n-Beziehung ausgedrückt.
Fremdschlüssel statt Beziehung. Ebenso zu vermeiden ist das Verwenden von
Fremdschlüsseln in einer Entität. Eine Beziehung zwischen Entitäten soll nicht
durch Hinzufügen von einem Fremdschlüssel sondern durch eine Beziehung
beschrieben werden.

Beispiel: Hier wurde versucht, die Entitäten Assistent
und Professor durch Hinzufügen der Schlüsselattribute der jeweils anderen
Entität zu verknüpfen. Die Beziehung zwischen zwei Entitäten wird in einem
EER-Diagramm allerdings durch eine Beziehung, in unserem Fall ‘ist zugeordnet’,
ausgedrückt, und nicht durch Einfügen von Fremdschlüsseln. (Ein weiteres Problem
entsteht in diesem Beispiel dadurch, daß der Fremdschlüssel bei der Entität
Professor steht, und daher eine 1:1- bzw. eine n:1-Beziehung in die falsche
Richtung bedeutet.)
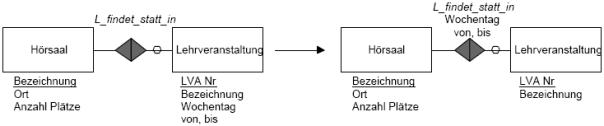
Zuordnung von Attributen zu Entität statt zu
Beziehung. In der folgenden Abb. ist
eine LVA derart modelliert, dass sie in mehreren Hörsälen und an mehreren Wochentagen
stattfinden kann. Daher ist es nicht zulässig, den Wochentag fix einmal bei der
LVA-Entität anzusiedeln, sondern ist der Termin bei der Beziehung von LVA zu
Hörsaal zu speichern.
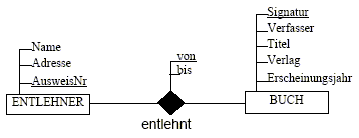
An einer Bibliothek können
Bücher entlehnt werden. Auf dem Entlehnschein werden die Signatur, Verfasser,
Titel, Verlag und Erscheinungsjahr des Buches und Name, Adresse und
Ausweisnummer des Entlehners vermerkt.
- Identifizieren Sie die Entities mit deren
Attributen
- Erkennen Sie die Relationships
- Zeichnen Sie das EER-Diagramm
Jeder Mitarbeiter arbeitet in
einem Raum; in jedem Raum arbeitet nur ein Mitarbeiter
Kunden vergeben Aufträge für
Projekte. Ein Kunde kann mehrere Projekte in Auftrag geben. Es gibt keine
Projekte, die von mehreren Kunden in Auftrag gegeben werden.
Mitarbeiter bearbeiten
Projekte. Ein Mitarbeiter kann mehrere Projekte bearbeiten. Ein Projekt wird
von mehreren Mitarbeitern bearbeitet. Die Stundenanzahl wird protokolliert.
Jedem Mitarbeiter ist ein
Bürostandort zugeordnet, jedem Bürostandort sind mehrere Mitarbeiter
zugeordnet.
Versuche ein EER-Modell zu
erstellen:
- Identifiziere Entitätstypen und Beziehungstypen
- Bestimme die Beziehungskomplexitäten
- Such nach sinnvollen Attributen
Die Darstellungsformen sind
entsprechend der vorgestellten Notation abzuändern!
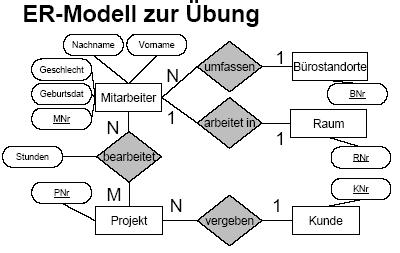
KUNDE (KNr)
PROJEKT (PNr, KNr)
MITARBEITER (MNr,
Geburtsdatum, Geschlecht, Nachname, Vorname, BNr)
BEARBEITET (PNr, MNr,
Stunden)
BÜROSTANDORTE (BNr)
RAUM (RNr, MNr)
Zeichnen Sie für den
folgenden Sachverhalt ein EER-Diagramm.
Eine Tierhandlung will den
Verkauf von Tieren mit Hilfe einer Datenbank abwickeln.
Die Tierhandlung verkauft
Tiere verschiedener Arten. Jede Art hat einen eindeutigen Namen, eine bestimmte
Lebenserwartung und wird normalerweise zu einem bestimmten Richtpreis verkauft.
Bei Säugetieren wird zusätzlich die Tragezeit, bei Reptilien die Anzahl der
Eier gespeichert.
Jedem Tier, das die
Tierhandlung besitzt, wird eine eindeutige Nummer gegeben. Es wurde an einem
bestimmten Tag geboren, ist männlich oder weiblich, und hat einen Vater und
eine Mutter, die ebenfalls der Tierhandlung gehören/ gehört haben.
Wenn das Tier verkauft wird,
so wird das Verkaufsdatum und der tatsächliche Verkaufspreis vermerkt.
Tiere werden in Käfigen
gehalten. Jeder Käfig hat einen eindeutigen Code.
Für jeden Käfig ist vermerkt,
welche Tiere sich in ihm befinden, wie groß er ist und wann er zum letzten Mal
gereinigt wurde. Jedes Tier in der Tierhandlung befindet sich in einem Käfig.
Aus Sicherheitsgründen wird
in der Datenbank verzeichnet, welche Arten gemeinsam in einem Käfig gehalten
werden können.
Auf die gesunde Fütterung der
Tiere wird großer Wert gelegt. Dazu wird für jede Art vermerkt, welche Menge
von den diversen Zusatzstoffen (z.B. Vitamine, Mineralien, etc. - diese
Unterscheidung soll nicht modelliert werden) ein Tier dieser Art pro Tag und
Kilogramm Körpergewicht zu sich nehmen muss.
Jedes Futtermittel hat einen
eindeutigen Namen, wird von einem bestimmten Lieferanten bezogen und ist noch
in einer bestimmten Menge vorrätig. Für die Lieferanten wird der eindeutige
Name, die Adresse, Telefonnummer und der Wochentag, an dem geliefert wird,
gespeichert.
Für jedes Futtermittel wird
verwaltet, welche Mengen an Zusatzstoffen in einem Kilogramm des Futters
enthalten sind.
Von jedem Angestellten wird
die SVNr., Name, Adresse, Gehalt, sowie die Tierarten, für die er ausgebildet
ist, gespeichert.
Die Darstellungsformen sind
entsprechend der vorgestellten Notation abzuändern!
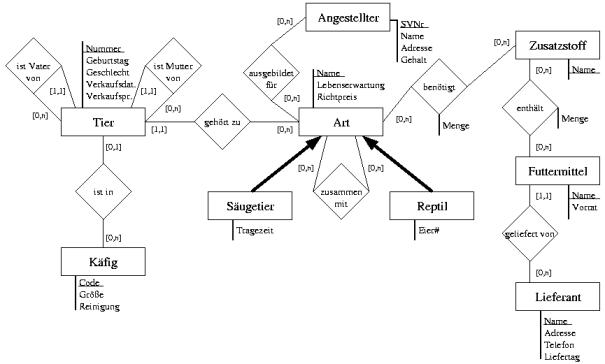
TIER (Nummer,
Geburtstag, Geschlecht, Verkaufsdatum, Verkaufspreis, Code, Name, Vater-Nummer,
Mutter-Nummer)
KÄFIG (Code, Größe,
Reinigung)
ART (Name,
Lebenserwartung, Richtpreis
SÄUGETIER (Name,
Tragezeit)
REPTIL (Name, Eier#)
ZUSAMMEN_MIT (Name1, Name2)
ANGESTELLTER (SVNr,
Name, Adresse, Gehalt)
AUSGEBILDET_FÜR (SVNr,
Name)
ZUSATZSTOFF (Name)
BENÖTIGT (Art-Name, Zusatzstoff-Name,
Menge)
FUTTERMITTEL (Name,
Vorrat, Lieferant-Name)
ENTHÄLT (Zusatzstoff-Name,
Futtermittel-Name, Menge)
LIEFERANT (Name,
Adresse, Telefon, Liefertag)
Dies sind die Testbeispiele,
die auch die Betriebsmanagement-Schüler lösen konnten (mussten).
Die österreichische Fluglinie
(ÖFL) wird durch das wirtschaftlich schlechte Umfeld auch zur
Restrukturierung der
EDV-Struktur gezwungen. Unter anderem soll auch die
Datenbank verkleinert und neu
entworfen werden.
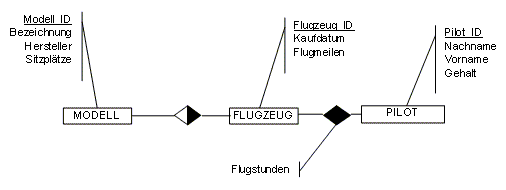
Für die angeschafften
FLUGZEUGe sollen das Modell, Kaufdatum und die geleisteten Flugmeilen in der
Datenbank gespeichert werden.
Das MODELL beinhaltet den Hersteller, die Modellbezeichnung,
die Anzahl der Sitzplätze.
Die PILOTEN der ÖFL werden
mit Nachname, Vorname und Gehalt gespeichert. Die von den Piloten
auf den jeweiligen
Flugzeugmodellen geleisteten Flugstunden sollen
ebenfalls aufgenommen werden.
Finden Sie geeignete
Entitäten und Attribute (ergänzen Sie Primärschlüssels wo es notwendig ist).
Entwerfen Sie die Datenbank
(Beziehungen) und leiten Sie daraus die notwendigen Tabellen und Attribute ab.
Lösung
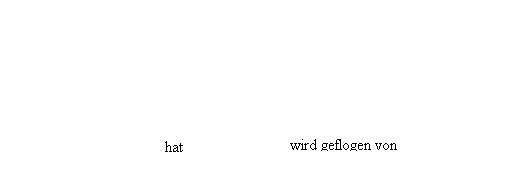

MODELL (Modell_ID,
Bezeichnung, Hersteller, Sitzplätze)
FLUGZEUG (Flugzeug_ID,
Kaufdatum, Flugmeilen, Modell_ID)
PILOT (Pilot_ID,
Nachname, Vorname, Gehalt)
WIRD_GEFLOGEN_VON (Flugzeug_ID,
Pilot_ID, Flugstunden)
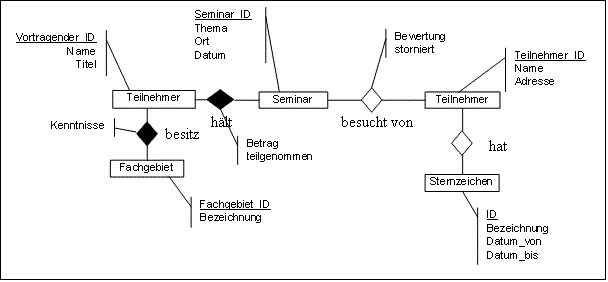
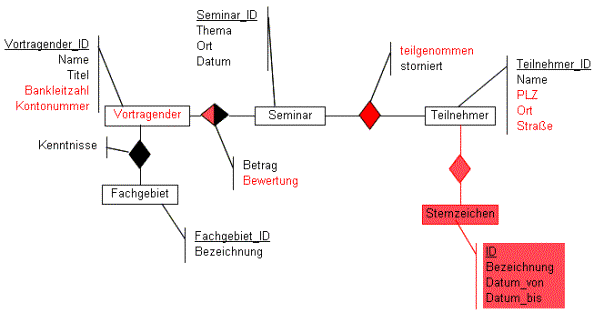
Als LeiterIn einer
Fortbildungsagentur haben Sie eine Firma beauftragt, eine Datenbank zu
entwerfen, um die Daten speichern zu können.
Zu den Referenten sind
Referenten_ID, Name, Titel, Bankleitzahl und Kontonummer zu speichern.
Bei den Teilnehmern sind
Teilnehmer_ID, Name, Postleitzahl, Ort, Straße zu speichern.
Die Referenten besitzen
Kenntnisse in bestimmten Fachgebieten (Fachgebiet_ID, Bezeichnung), die jeweils
individuell beurteilt werden ("gut", "Spezialist",
"Experte", ...).
Die angebotenen Kurse
besitzen eine Kurs_ID, Thema, Ort und ein Datum.
Die Kurse sind so angelegt,
dass sie immer auch von mehreren Referenten abgehalten werden können.
Welchen Betrag und welche
Bewertung ein Referent für eineinen Kurs bekommt
soll ebenfalls gespeichert
werden.
Beim Teilnehmer wird je Kurs
vermerkt, ob er/sie an einem Kurs tatsächlich teilgenommen
hat oder ob er/sie die
Teilnahme storniert hat.
Die Aufragnehmer legen Ihnen
folgendes EER-Diagramm vor. Beurteilen Sie, ob Ihre Vorgaben
erfüllt wurden und
kennzeichnen Sie jene Punkte, die den Vorgaben nicht entsprechen.
Lösung:

SQL bedeutet Structured Query Language und ist
ein akzeptierter Industriestandard für die Definition und Manipulation von
Datenbanken. Weiters ist es möglich, Transaktionen kontrolliert auszuführen und
bei Fehlschlag wieder rückgängig zu machen. SQL-Anweisungen werden als
Zeichenkette an die Datenbank geschickt und dort verarbeitet. Hier benötigen
wir nur Datenbankabfragen und einfache Datenbankmanipulationen mittels SQL, und
verzichten daher auf weitergehende Funktionalitäten. Im Text verwenden wir
folgende Schreibweise für Syntaxbeschreibungen.
Tab. Konventionen
der Meta-Syntax.

Die geschwungenen und eckigen Klammern, die
Unterstreichungen und senkrechte Striche dienen der Syntaxbeschreibung und sind
bei den konkreten Anfragen wegzulassen. Runde Klammern werden hingegen von SQL
verlangt.
Um nun weiter arbeiten zu können, wollen wir einen
Blick auf einige Datentypen werfen, die zur Verfügung gestellt werden:
Tab. Interbase-Datentypen

SQL stellt folgende Anweisung zur Verfügung, um eine
Tabelle anzulegen.
CREATE TABLE tabellenname (attribut1 typ {Optionen}
{, attributN typ {Optionen} , {Zusatzoptionen});
Als Attribut- und Tabellennamen sind Wörter –
bestehend aus alphanumerischen Zeichen und Unterstrich “_” – erlaubt. Als
Optionen (eigentlich Einschränkungen, engl. constraints) kann
angegeben werden, ob das Feld auf alle Fälle mit Daten gefüllt werden muss
(Option NOT NULL) oder ob es sich bei dem betreffendem Attribut um einen
einfachen Primärschlüssel handelt (Option PRIMARY KEY).
In den Zusatzoptionen können zusammengesetzte
Schlüssel angegeben werden:
PRIMARY KEY (attribut1,....,attributN).
Auch Referenzen auf andere Tabellen können realisiert
werden:
FOREIGN KEY(schlüssel1) REFERENCES tabellenname(schlüssel2)
Dieser Ausdruck bewirkt, dass eine logische
Verknüpfung hergestellt wird um sicherzustellen, dass “schlüssel1” in
der gerade angelegten Tabelle sich auf den korrespondierenden Schlüssel in der
Tabelle “tabellenname” bezieht. Die angegebenen Attribute “schlüssel1”
und “schlüssel2” müssen allerdings auch als Schlüssel oder zumindest als
Teilschlüssel in der Tabelle “tabellenname” angegeben sein, um sicherzustellen,
dass die Referenzierung auch tatsächlich existiert. Allerdings können diese
Referenzen nur dazu genützt werden, um sicherzustellen, dass diese elementaren
Integritätsbedingungen nicht verletzt werden. Das heißt, dass die references-Anweisung
nur sicherstellt, dass zu dem angegebenen “schlüssel1” in der Tabelle
“tabellenname” auch tatsächlich ein “schlüssel2” mit demselben Wert existiert.
Weiters können auch Integritätsbedingungen angegeben
werden:
CHECK Ausdruck
Ausdruck ist
hier ein logischer Ausdruck, wie etwa attribut1 < attribut2.
Wir legen die Tabellen “Autor” und “Buch” an:
CREATE TABLE Buch
(BuchNr INTEGER NOT NULL PRIMARY KEY,
Titel VARCHAR(30) NOT NULL,
CHECK ((BuchNr<=999999) AND (BuchNr>=0)));
CREATE TABLE Autor
(SVNr INTEGER NOT NULL PRIMARY KEY,
Name VARCHAR(30) NOT NULL,
CHECK ((SVNr <= 9999) AND (SVNR >= 0)));
Danach können wir die Verbindungstabelle “schreibt”
anlegen:
CREATE TABLE schreibt (BuchNr INT NOT NULL, SVNr INT
NOT NULL, PRIMARY KEY (BuchNr, SVNr),
foreign key(BuchNr) references Buch(BuchNr), foreign key(SVNr)
references Autor(SVNr),
check ((BuchNr <=
999999) AND (SVNr <= 9999)));
Hiermit haben wir ein Datenbankschema angelegt. Zu
beachten ist hier, dass wir uns die letzte Zeile des obigen Statements
eigentlich hätten sparen können, da die Referenzen von “BuchNr” und “SVNr”
schon in ihren Tabellen auf ihren Wertebereich (vier- bzw. fünfstellig)
überprüft werden.
Die Anweisung 'drop table' wird verwendet, um eine
nicht mehr benötigte Tabelle zu entfernen. Die angegebenen Tabellen mit allen
darin enthaltenen Daten werden vollständig gelöscht.
DROP TABLE tabellenname
{,tabellenname};
Manchmal kann es vorkommen, dass man nachträglich die
Struktur einer Tabelle verändern will. SQL stellt dafür den “alter
table”-Befehl zur Verfügung. Um ein neues Attribut einzuführen, verwendet man
die add-Klausel:
ALTER TABLE tabellenname ADD attributname
typ;
Stellen wir uns nun vor, dass die Analyse des
Problems, das wir oben modelliert haben, unvollständig ist und es noch
notwendig ist, für alle Bücher den Preis mitzuspeichern. Dies geschieht durch die
folgende Anweisung:
ALTER TABLE Buch ADD Preis FLOAT;
Die folgende Anweisung löscht ein Attribut aus der
Tabelle:
ALTER TABLE tabellenname DROP attributname;
Es gibt in SQL die folgende Möglichkeit, Daten in eine
Tabelle einzufügen:
INSERT INTO tabellenname
[(attribut1, attribut2, .... attributN)] VALUES (wert1, wert2, ....
wertN);
Mit diesem Befehl wird ein neuer Datensatz (ein neuer
Tupel bzw. eine neue Zeile in der Tabelle) angelegt und die Attribute attribut1,
attribut2,... attributN mit den Werten wert1, wert2, ... wertN gefüllt.
Falls die Werte für alle Attribute bekannt sind und die Werte in der richtigen
Reihenfolge angeführt werden, so kann die Angabe der Attribute weggelassen
werden. Die richtige Reihenfolge bedeutet hier, dass die Werte für die
einzelnen Attribute in genau der Reihenfolge angegeben werden, in der sie beim
Anlegen der Datenbank angegeben wurden. Werden neue Attribute zu einer Tabelle
hinzugefügt, so werden diese am Ende angefügt. Beispiel:
INSERT INTO Autor (Name, SVNr) VALUES (“Meier”, 0000);
ist äquivalent zu
INSERT INTO Autor
VALUES (0000, “Meier”);
Um in den folgenden Abschnitten genügend Daten zur
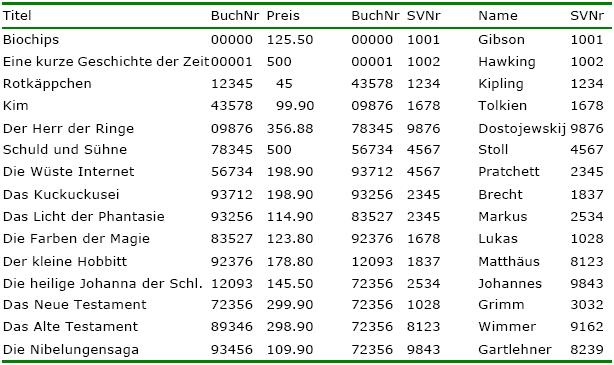
Verfügung zu haben, sollten die Tabellen mit den folgenden Tupeln gefüllt werden:
Tab. "Buch",
"schreibt", "Autor"
Bisher haben wir Befehle betrachtet, die es uns
ermöglichen, die Struktur einer Tabelle zu verändern. Nun wollen wir daran
gehen, die Daten einer Tabelle zu modifizieren bzw. zu löschen.
Um bestehende Datensätze zu modifizieren verwendet man
folgenden Befehl:
UPDATE tabellenname
SET attributname
= value {, attributname = value}
[WHERE Prädikat];
Jedem Attribut wird der Wert zugewiesen, der hinter
dem Gleichheitszeichen steht. Es werden allerdings alle Tupel bearbeitet –
daher ist es in den meisten Fällen sinnvoll eine where-Klausel
anzugeben, um nur ausgewählte Tupel zu ändern. Wir wollen nun den Preis des
Buches mit dem Titel “Kim” auf 109.90 ändern. Dazu verwenden wir folgende
Abfrage:
UPDATE Buch SET Preis=109.90 WHERE Titel=”Kim”;
Die folgende Abfrage hätte zu Wirkung, dass alle
Bücher den Preis 109.90 erhalten:
UPDATE Buch SET Preis=109.90;
Seien Sie also stets sehr aufmerksam, wenn Sie den
update-Befehl verwenden, da durch Flüchtigkeit des Programmierers sehr leicht
ungewollt Daten überschrieben werden können. Da es aber immer wieder vorkommt,
dass trotz großer Vorsicht Daten gelöscht werden, ist es sehr wichtig, dass
regelmäßige Backups der Arbeitsdatenbank angelegt werden. Vor allem vor dem
Testen von neuen Programmteilen, die auf die Datenbank zugreifen, ist es
ratsam, die Datenbank zu sichern.
Der Befehl zum Löschen einzelner oder aller Datensätze
einer Tabelle lautet:
DELETE FROM tabellenname
[where Prädikat];
Wie schon beim Modifizieren von Datensätzen dient hier
die optionale where-Klausel dazu, dass nicht alle Datensätze, sondern
gezielt Datensätze, die der Bedingung der where-Klausel genügen, gelöscht
werden.
DELETE FROM Buch WHERE Titel=”Das Alte
Testament”; /* löscht das Buch “Das Alte Testament” */
DELETE FROM Buch; /* löscht alle Tupel
in dieser Tabelle */
Die wohl wichtigste Fähigkeit einer Datenbanksprache
ist ihre Möglichkeit Daten abzufragen. SQL stellt den SELECT-Befehl zur
Verfügung, mit dem sehr mächtige Anfragen (oder Queries) an die
Datenbank geschickt werden können. Die Datenbank antwortet auf diese Anfragen
in Form einer Tupel-Menge, also einer Liste von Tupeln, die den angegebenen
Kriterien entsprechen.
Leider gibt es für die verschiedenen Datenbanksysteme
unterschiedliche Realisierungen des SELECT-Befehls, wodurch manche Datenbanken
gewisse Teilfunktionalitäten des SELECTs nicht beherrschen oder eine leicht
abgeänderte Syntax verlangen. Genauere Informationen entnehmen Sie den
jeweiligen Handbüchern.
Da mit dem SELECT-Befehl sehr mächtige und auch
syntaktisch komplexe Ausdrücke an die Datenbank geschickt werden können, wollen
wir uns vorerst nur mit der Grundstruktur des SELECT-Befehls befassen:
SELECT attributname {, attributname}
FROM tabellenname {, tabellenname}
[WHERE Prädikat];
In der FROM-Klausel wird der Name der Tabelle
angegeben, auf die die Datenbank die Datenabfrage anwenden soll. Es können auch
mehrere Tabellennamen angegeben werden, falls sich die Anfrage auf mehrere
Tabellen bezieht.
Die Angabe von einem oder mehreren Attributnamen in
der SELECT-Klausel gibt an, welche Attribute in der Ergebnismenge angeführt
werden sollen. Klarerweise muss man darauf achten, dass diese Attributnamen in
den angegebenen Tabellen auch tatsächlich existieren. “*” zeigt alle Attribute
einer Tabelle als Ergebnismenge an.
Um nun alle Einträge einer Tabelle (hier die Tabelle
“Buch”) zu betrachten, können Sie die folgende Abfrage verwenden: SELECT * FROM
Buch; (Semikolon nicht vergessen.)
Das Prädikat in der optionalen WHERE-Klausel
spezifiziert die Bedingungen, die Daten erfüllen müssen, damit sie in das
Resultat der Anfrage aufgenommen werden – man spricht hier auch oft von Suchbedingungen.
Ein einfaches Prädikat hat die Form operand1 operator operand2.
Operanden können Attributnamen oder Konstanten sein.
Als Operatoren kann man eines der folgenden Symbole verwenden, die hier die
wohlbekannte Bedeutung haben: =, >, <, <=, >= und != (d.h. nicht
gleich). Mehrere einfache Prädikate können mittels AND, OR und NOT und runden
Klammern “(” bzw. “)”verknüpft werden.
Ein Beispiel für eine Abfrage mit unserem obigem
Beispiel 'Autor schreibt Buch' wäre
SELECT SVNr FROM
Autor
WHERE Name=”Brecht”;
Diese Anfrage liefert die Sozialversicherungsnummern
aller Autoren mit dem Namen Brecht zurück. Zu beachten ist hier, dass
Stringkonstanten unter doppeltes Anführungszeichen gestellt werden müssen,
Zahlenkonstanten aber nicht.
Wir wollen nun den Fall betrachten, dass wir eine
Buchnummer (z.B. 72356) kennen und alle Autoren mitsamt
Sozialversicherungsnummer auflisten wollen, die an diesem Buch gearbeitet
haben. Mit unserem einfachen SELECT ist dies nicht möglich, daher wollen wir
nun eine erweiterte Syntax betrachten:
SELECT [ALL |
DISTINCT] [Alias.]attributname {, [Alias.]attributname}
FROM tabellenname [Alias] {, tabellenname [Alias]}
[WHERE Prädikat];
Der Unterschied zu unserer ersten Definition liegt nun
darin, dass wir für jeden Tabellennamen einen Alias (eine Ersetzung)
angeben können. Weiters können wir entscheiden, ob alle doppelt vorkommenden
Tupel in der Ergebnismenge auch doppelt angegeben werden (Option ALL) oder ob
doppelte Einträge nur einmal ausgegeben werden (Option DISTINCT).
Wir wollen wieder unsere Beispieldatenbank mit 'Autor
schreibt Buch' betrachten und versuchen eine Abfrage anzugeben, die die oben
geforderte Funktionalität erfüllt.
Wenn wir uns die drei Tabellen “Autor”, “Buch” und
“schreibt” ansehen, stellen wir fest, dass die Verbindung zwischen “Autor” und
“Buch” über “schreibt” erfolgt. “Schreibt” enthält also auch die von uns
gesuchte “BuchNr”. Da “schreibt” direkt mit “Autor” verbunden ist, verwenden
wir also “schreibt”, um alle Bücher mit der BuchNr 72356 zu erhalten.
Hier nun eine passende Anfrage:
SELECT DISTINCT A.Name,
A.SVNr
FROM Autor A,
schreibt s
WHERE A.SVNr=s.SVNr
and s.BuchNr=72356;
Hier haben wir nun ein Beispiel für Aliase: Der
Tabelle “Autor” wird der Alias “A” zugewiesen und “schreibt” erhält den Alias
“s”. Dieses Aliassystem ist sehr hilfreich, wenn es darum geht, Attribute aus
verschiedenen Tabellen zu vergleichen. Beachten Sie, dass die einzelnen
Attribute mittels Alias.Attributname angesprochen werden. Doch nun etwas
genauer zu unserer Anfrage.
In der where-Klausel vergleichen wir die
Sozialversicherungsnummer der Tabelle “Autor” mit dem entsprechenden Feld in
der Tabelle “schreibt” auf Gleichheit. SQL liefert daraufhin alle in der select-Klausel
angegebenen Felder zurück, die zu Tupeln gehören, die das Prädikat in der where-Klausel
erfüllen. Doppelt auftretende Tupel werden hier nur einmal ausgegeben.
In unserem Fall sind das alle Tupel aus der Tabelle
“Autor”, deren Attribut “SVNr” gleich der “SVNr” eines Tupels aus der Tabelle
“schreibt” ist, dessen “BuchNr” gleich der angegebenen Konstante ist.
Doch damit nicht genug: Jetzt wollen wir bestimmen,
wie viele Bücher der Autor mit dem Namen “Tolkien” geschrieben hat. Dazu
verwenden wir eine so genannte Aggregatfunktion, nämlich COUNT. Hier die
zugehörige Anfrage:
SELECT COUNT(s.SVNr)
FROM schreibt s,
Autor a
WHERE s.SVNr=a.SVNr
AND a.Name=”Tolkien”;
Als Ergebnis dieser Anfrage erhalten wir die Zahl 2,
nämlich die gesuchte Anzahl von Büchern, die von Tolkien geschrieben wurden
(und in unserer Datenbank erfaßt sind). Natürlich gibt es auch noch andere
Aggregatfunktionen. Hier ein kurzer Überblick über häufig benötigte
Aggregatfunktionen:
Tab. 4 Aggregatfunktionen

Allerdings kann es hier zu einem Problem kommen.
Stellen Sie sich vor, Sie wollen eine Anfrage absetzen, die sowohl “reine”
Attribute (d.h. Attribute ohne Aggregatfunktion) als auch die Anzahl der
Attribute ausgeben soll. Eine Möglichkeit für eine derartige Abfrage, wäre nach
unserem jetzigen Wissensstand SELECT Name, COUNT(Name) FROM Autor; Versuchen
wir jetzt, ohne uns eine konkrete Ergebnismenge anzusehen, zu bestimmen, wie
diese aussehen könnte. Als erstes geben wir alle Namen der Autoren aus. Dann sollen
wir auch noch die Anzahl der Autoren ausgeben. Wir stellen hier also fest, dass
der erste Teil der select-Klausel mehrere Namen zurückliefern würde,
COUNT hingegen genau eine Zahl zurückliefert.
SQL ist leider nicht in der Lage derartige
Ergebnismengen zu generieren. Die obige Anfrage ist daher so nicht möglich.
Daher wollen wir noch eine zusätzliche Möglichkeit
einführen, um der obigen Misere zu entgehen. Am besten wäre hier wohl eine
Funktion, die angibt, wie die einzelnen Ausprägungen der Tupel zu gruppieren
sind. Es soll also jeweils angegeben werden, wie viele Tupel sich in einer
Gruppe befinden. Hier nun die erweiterte Syntax eines derartigen
select-Befehls:
SELECT [ALL | DISTINCT] [Alias.]attributname {,
[Alias.]attributname}
FROM tabellenname
[Alias] {, tabellenname [Alias]}
[WHERE Prädikat]
[GROUP BY [Alias.]attributname
{, [Alias.] attributname} [HAVING Prädikat]];
Die group by-Klausel hat den Effekt, dass die
Ergebnistupel entsprechend ihren Ausprägungen (z.B. Titel=”Kim”)
zusammengefasst werden. Mittels der optionalen having-Klausel können die
Bedingungen aus der where-Klausel noch erweitert werden. Mit anderen
Worten: Zuerst werden jene Tupel in die Ergebnismenge aufgenommen, die der where-Klausel
genügen und dann werden jene Tupel wieder eliminiert, die der having-Klausel
nicht genügen.
Group by-Ausdrücke
können jedes beliebige Attribut der Tabellen in der from-Klausel
verwenden, egal ob sie in der select-Klausel aufscheinen oder nicht.
Fehlt die group by-Klausel, so wird das Ergebnis als eine einzige Gruppe
aufgefasst.
Hier also eine korrekte Version der obigen Anfrage:
SELECT Name, COUNT(Name)
FROM Autor
GROUP BY Name;
Wenn wir nun die Ergebnismenge betrachten, wird für
jeden Autor angegeben, wie oft er in der Tabelle vorkommt.
Es gibt allerdings auch noch Regeln für die Verwendung
von group by-Klauseln:
Bei Verwendung der group by-Klausel muß jeder
Ausdruck in der select-Klausel entweder eine Konstante, eine
Aggregatfunktion (wie etwa SUM, COUNT) oder exakt ein Ausdruck der group by-Klausel
sein.
SELECT BuchNr, Titel, MAX(Preis) FROM Buch
GROUP BY BuchNr; /* Falsch, da “Titel” nicht in
der group by-Klausel aufscheint */
SELECT BuchNr, Titel, MAX(Preis) FROM Buch
GROUP BY BuchNr, Titel;
SELECT Name, MIN(Preis), MAX(Preis) FROM Buch
GROUP BY Name; /* Richtig */
Wenn Sie die Ergebnismenge betrachten, so stellen Sie
fest, dass für jedes Buch der Name und sein minimaler und maximaler Preis
ausgegeben werden (diese sind bei den oben angegebenen Daten in unserem
Beispiel identisch).
Eine weitere zusätzliche Funktionalität von
SELECT-Anweisungen ist die optionale order by-Klausel:
SELECT [ALL |
DISTINCT] [Alias.]attributname {, [Alias.]attributname}
FROM tabellenname
[Alias] {, tabellenname [Alias]}
[WHERE Prädikat]
[GROUP BY [Alias.]attributname {, [Alias.] attributname} [HAVING Prädikat]]
[ORDER BY [Alias.]attributname
[ASC | DESC ] {, [Alias.] attributname [ASC | DESC ]}];
Mittels der order by-Klausel ist es möglich die
Reihenfolge der Tupel in der Ergebnismenge festzulegen. Die Ergebnismenge wird
nach den angegebenen Attributen entweder aufsteigend (ASC, engl. ascending)
oder absteigend (DESC, engl. descending) sortiert. Wenn keine Ordnung angegeben
wird, ist die Standardeinstellung aufsteigend. Wenn mehrere Attribute angeben
werden, so wird zuerst nach weiter vorne stehenden Attributen sortiert.
Bei gleichzeitiger Anwendung von einer order by-Klausel
und DISTINCT dürfen in der order by-Klausel keine Attribute angegeben
werden, die nicht in der select-Klausel vorkommen.
Ein Beispiel: SELECT DISTINCT Titel, Preis FROM Buch
ORDER BY Preis DESC, Titel ASC;
Es werden also alle Titel und Preise sortiert
ausgegeben. Die Sortierung erfolgt hier in erster Linie nach dem Preis
(absteigend) und in zweiter Linie nach dem Titel (aufsteigend).
Bisher konnten wir nur Abfragen betrachten, die direkt
zwei Tabellen miteinander vergleichen (z.B. alle Autoren angeben, die an einem
bestimmten Buch mitgearbeitet haben, siehe Beispiel oben). Allerdings können
wir keine Teilergebnismengen miteinander vergleichen. Dies kann notwendig
werden, wenn wir zum Beispiel alle Autoren aus dem 'Autor schreibt
Buch'-Beispiel betrachten wollen, die kein Buch geschrieben haben. Dafür
müssten wir eine Möglichkeit finden, um die Menge aller Autoren mit der Menge
der Autoren, die kein Buch geschrieben haben, zu vergleichen. Diese Möglichkeit
wird durch die Sub-select-Anweisung zur Verfügung gestellt.
Sub-selects sind nicht anderes als die Erweiterung des
Prädikats in der where-Klausel, um Vergleiche zwischen
SELECT-Anweisungen zu ermöglichen. Beispiel:
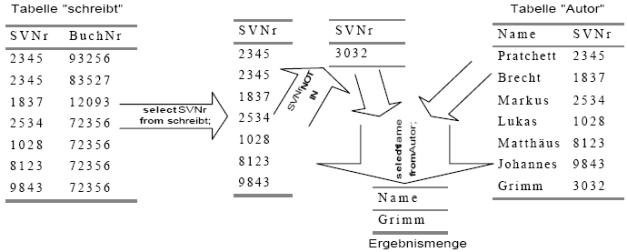
SELECT Name FROM Autor
WHERE SVNr NOT IN (SELECT SVNr FROM schreibt);
In diesem Beispiel werden zuerst alle
Sozialversicherungsnummern aus der Tabelle “schreibt” selektiert und dann diese
Sozialversicherungsnummern mit allen Sozialversicherungsnummern aus der Tabelle
“Autor” verglichen. Durch den Vergleichsoperator NOT IN werden dann nur
diejenigen Tupel in die Ergebnismenge aufgenommen, deren Attribut “SVNr” nicht
in der Ergebnismenge des Sub-select zu finden sind.
Abb. SELECT mit
Sub-select
Mit anderen Worten: Ein Prädikat in der where-Klausel
kann auch ein Vergleich zwischen select-Anweisungen sein. In diesen select-Anweisungen
können weitere Sub-select-Anweisungen vorkommen.
Als Vergleichsoperatoren können wir folgende Ausdrücke
verwenden:
<Ausdruck> bezeichnet ein Attribut oder
eine durch Beistriche getrennte Folge von Attributen
<Operator> bezeichnet “=” oder “!=” (ungleich)
<Abfrage> beschreibt eine Abfrage, d.h. eine weitere select-ANWEISUNG
Tab. Syntax von
Sub-selects

Damit hätten wir alle relevanten Arten von
Select-Anweisungen bestimmt. Allerdings soll hier nicht verschwiegen werden,
dass diese Definitionen noch nicht vollständig sind. Der Select-Befehl ist noch
weitaus mächtiger – Interessierte seien hier wieder an weiterführende
Informationen zum Thema Datenbanksysteme verwiesen.
Beispiele zu SELECT-Anweisungen
Als erstes wollen wir eine Abfrage erstellen, die uns
das teuerste Buch zurückliefert:
SELECT Titel, Preis
FROM Buch
WHERE Preis =
ALL (SELECT MAX(Preis) FROM Buch);
Der nächste interessante Schritt ist auch noch den
Autor zu diesem teuersten Buch anzugeben:
SELECT a.Name, b.Titel, b.Preis
FROM Buch b, Autor a, schreibt s
WHERE (b.Preis =
all (select max(Preis) from Buch)) and (b.BuchNr=s.BuchNr) and (s.SVNr=a.SVNr);
Da es in SQL oft mehrere Möglichkeiten gibt,
identische Ergebnismengen zu erzeugen, wird hier noch eine derartige Abfrage
angegeben. Die folgende Abfrage liefert eine identische Ergebnismenge:
SELECT DISTINCT a.Name,b.Titel,b.Preis
FROM Buch b,
Autor a
WHERE (b.Preis =
all (select max(Preis) from Buch)) and b.Buchnr= any (select Buchnr from
schreibt where
SVNr=a.SVNr);
Als letztes Beispiel betrachten wir zwei Möglichkeiten
den Durchschnittspreis aller Bücher anzugeben:
SELECT avg(Preis)
FROM Buch;
SELECT sum(Preis)/COUNT(Preis)
FROM Buch;
Sie sehen also, dass SQL sogar zu einfachen
Berechnungen fähig ist. Mittels dieser Berechnungen wollen wir nun eine Abfrage
entwerfen, die das (oder die) teuersten Bücher zusammen mit der Differenz des
Preises zum Durchschnittswertes ausgibt:
SELECT a.Name,b.Titel,b.Preis,
b.Preis-avg(b1.Preis)
FROM Buch b, Buch b1, Autor a, schreibt s
WHERE (b.Preis =
all (select max(Preis) from Buch)) and (b.BuchNr=s.BuchNr) and (s.SVNr=a.SVNr)
GROUP BY a.Name,b.Titel,b.Preis;
Eine Besonderheit ist, dass die Tabelle “Buch” in der
from-Klausel zweimal vorkommt. Das liegt daran, dass für den Alias “b” alle
Tupel selektiert werden, die den maximalen Preis aufweisen.
Im Alias “b1” hingegen werden keine Tupel ausgewählt –
es werden also alle Tupel in die Mittelwertberechnung miteinbezogen. Versuchen
Sie selbst, was passiert, wenn sie statt “b1.Preis” einfach “b.Preis”
schreiben.
Ein “sauberes” Datenbankdesign sollte in dritter
Normalform (3NF) sein. Eine exakte, formale Definition dieses Zustandes ist
nicht ganz einfach und kann hier nicht gegeben werden. Im Wesentlichen geht es
dabei zunächst darum, die Wertebereiche von Attributen “atomar” zu halten. Im
folgenden Negativbeispiel ist es unmöglich, eine Abfrage der Art “Welche Filme
werden im Artis-Kino gespielt?” durchzuführen.

Außerdem sollen inkonsistente Zustände (Anomalien)
vermieden werden, die beim Eintragen oder Löschen von Daten in unbedacht
entworfenen Datenbanken auftreten können. Dazu muss Information zu
verschiedenen Entitäten auch in verschiedenen Tabellen gespeichert werden:
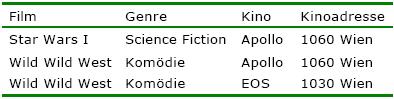
Nehmen wir an, im EOS-Kino wird der Film “Wild Wild
West” nicht mehr gespielt; wir löschen also den Datensatz. Dabei verlieren wir
aber gleichzeitig alle Informationen über das Kino (Adresse)! Analoges
passiert, wenn zum Beispiel das Apollo-Kino “Star Wars” nicht mehr auf dem
Spielplan hat: Die Informationen über den Film werden ebenfalls gelöscht.
Außerdem werden Daten unnötig mehrfach gespeichert (im Beispiel die Adresse des
Apollo-Kinos). Zur Lösung des Problems müssen die Daten in drei Tabellen
aufgeteilt werden (es handelt sich ja um eine m:n-Beziehung): Film(FilmID,
Titel, Genre), Kino(KinoID, Name, Adresse) und Spielt(FilmID, KinoID).
Ein korrekt aus einem sauberen EER-Diagramm
abgeleitetes Relationenmodell ist in aller Regel bereits in 3NF und kennt diese
Probleme nicht. Die Daten liegen in getrennten Tabellen und werden bei Bedarf
über ihre Schlüssel wieder in Zusammenhang gebracht. Dieser Vorgang wird als Join
bezeichnet. Das geschieht über ein entsprechendes Statement in der WHEREKlausel:
SELECT Titel, Genre, Name, Kinoadresse
FROM Film, Kino, Spielt
WHERE Film.FilmID=Spielt.FilmID AND Kino.KinoID=Spielt.KinoID
SQL kennt aber auch eine elegantere Möglichkeit, die
den Zweck der Verknüpfung hervorhebt:
SELECT Titel, Genre, Name, Kinoadresse
FROM (Film JOIN Spielt ON Film.FilmID=Spielt.FilmID)
JOIN Kino ON Kino.KinoID=Spielt.KinoID
SQL kennt auch eine Möglichkeit, um häufig benutzte
SELECT-Anweisungen (z.B. “maßgeschneiderte” Ausschnitte aus großen Tabellen für
bestimmte Benutzer, Routineabfragen oder Zwischenergebnisse für komplexe
Abfragen) abzulegen. Dazu können Ansichten definiert werden, auf die in der
Folge wie auf eine Tabelle zugegriffen werden kann (das Einfügen von Daten ist
je nach Art der der Ansicht zugrundeliegenden Abfrage im Allgemeinen aber nicht
mehr möglich). Eine View wird angelegt wie folgt:
CREATE VIEW N ame AS SELECT …
Jede zulässige SELECT-Anweisung kann als View
definiert werden.
Der folgende Abschnitt versucht, den Einstieg mit
einer Schritt-für-Schritt-Anweisung für den Zusammenbau einer Select-Anweisung
zu geben und einige häufige Stolpersteine aus dem Weg zu räumen. Die gegebenen
Hinweise sind aber keineswegs als allgemeingültiger Algorithmus zu verstehen
und können das Verständnis der Materie und die nötige Übung nicht ersetzen!
1. Einen Überblick über die
Tabellendefinitionen (Relationenschema) verschaffen. Bei größeren Datenbanken
ist zusätzlich auch das EER-Diagramm hilfreich.
2. Welche Informationen sollen
ausgegeben werden? Zu welchen Relationen gehören die entsprechenden Attribute?
Über welche Schlüssel sind diese miteinander verbunden? Mit diesen
Informationen können die für die Abfrage benötigten Tabellen und Joinattribute
bestimmt werden.
2a. Ist es notwendig, Duplikate
auszuschließen (SELECT DISTINCT)? Diese treten v.a. auf, wenn Tabellen
verknüpft werden. Betrachten wir zum Beispiel folgende Datenbank:

Wollen wir nun nur wissen,
in welchem Bezirk wir einen Film sehen können (SELECT FILMTITEL, PLZ FROM FILM,
KINO, SPIELT WHERE FILM.FILMID = SPIELT.FILMID AND KINO.KINOID = SPIELT.KINOID)
werden wir SELECT DISTINCT wählen, da wir sonst zweimal “Star Wars I, 1060”
erhalten würden. Bei Zählaufgaben (siehe weiter unten) wird der Ausschluss von
Duplikaten aber möglicherweise wiederum unerwünscht sein: Wir könnten zählen
wollen, wie oft ein Film pro Bezirk gespielt wird.
2b. Berechnungen, die nur
jeweils Attribute innerhalb eines Tupels betreffen, sind ebenso einfach wie
selten (z.B. Spieldauer als letztes_mal_gezeigt – erstes_mal_gezeigt).
Komplizierter wird es,
wenn Berechnungen über eine Anzahl Datensätze durchgeführt werden sollen (z.B.
Durchschnitt der Umsätze aller Kinos pro Bezirk). Hier kommen die
Aggregatfunktionen zum Einsatz (z.B. SUM oder AVG). Diese Funktionen
berücksichtigen alle Tupel, wenn ihnen nicht über GROUP BY mitgeteilt wird, auf
welche Untergruppen sie sich beziehen sollen (z.B. eben jeden Bezirk). Sie
werden dann für jede Gruppe von Datensätzen berechnet, für die die Werte der
Attribute, nach denen gruppiert wurde, gleich sind.
Bei der Verwendung von
Aggregatfunktionen sorgt gerne für Verwirrung, dass eine Aggregatfunktion konsequenterweise
genau ein Tupel erzeugt; bei Verwendung von GROUP BY enthält das Ergebnis ein
Tupel pro unterschiedlicher Ausprägung oder Kombination unterschiedlicher
Ausprägungen des oder der Attribute, nach denen gruppiert wurde. Deshalb können
auch nur genau diese Attribute (ohne Aggregatfunktion) selektiert werden – die
Werte der anderen wurden ja bereits durch die Aggregatfunktion zusammengefasst!
(Es ist jedoch möglich, ein Attribut, nach dem gruppiert wird, nicht zu
selektieren.)
Zum einfachen Sortieren
der Ausgabe (z.B. “Kinos, aufgestellt nach Bezirken”) ist GROUP BY nicht
notwendig; für solche Zwecke ist ORDER BY gedacht.
Eine weitere häufige
Schwierigkeit lauert in Anfragen, bei denen pro Tupel auf Grundlage von
Ergebnissen von Aggregatfunktionen weitere Berechnungen durchgeführt werden
sollen, für die einzelne Werte benötigt werden, aus denen die Aggregatfunktion
berechnet wurde (z.B. Anteil jedes Kinos am Gesamtumsatz). In diesem Fall kann
die Berechnung des Aggregatwertes in eine weitere SELECT-Anweisung
ausgegliedert werden (temporäre Tabelle oder View). Alternativ besteht die
Möglichkeit, die benötigte Tabelle ein weiteres Mal unter einem anderen Alias
in die FROM-Klausel aufzunehmen und die Aggregatfunktion über diesem Alias zu
berechnen (z.B. SELECT f1.Preis, f1.Preis-avg(f2.preis) FROM film f1, film f2).
3. Welche Datensätze sind
interessant und sollen ausgewählt werden? In der WHERE-Klausel werden die
gewünschten Bedingungen über den Attributen festgelegt, auch Auswahl in
Abhängigkeit von Berechnungsergebnissen zwischen Attributen ist möglich.
3a. Beziehen sich
Auswahlkriterien auf Ergebnisse von Aggregatfunktionen (gleichgültig, ob diese
in der Ausgabe aufscheinen oder nicht)? Wenn ja, werden diese (und nur diese)
in der HAVING-Klausel angegeben.
3b. Müssen zur Beurteilung, ob
ein Tupel in die Ergebnismenge aufgenommen wird oder nicht, mehrere andere
betrachtet werden und geht diese Betrachtung über einfaches Zählen oder andere
durch Aggregatfunktionen durchführbare Berechnungen hinaus (z.B. “ In welchen
Bezirken spielt kein Kino ‚Star Wars I‘?”) In solchen Fällen ist die Verwendung
eines Sub‑SELECT notwendig.
4. Zuletzt können noch Bezeichnungen
für die selektierten Felder gewählt (vor allem wichtig bei berechneten,
z.B.: SELECT verkaufspreis – einkaufspreis AS spanne) und die gewünschte Reihenfolge
der Tupel in der Ergebnismenge festgelegt werden (ORDER BY).
Die angegebene Reihenfolge ist nur als ungefähre
“Marschrichtung”, nicht als strikter zeitlicher Ablauf zu verstehen: In der
Regel haben “spätere” Teilschritte auch Rückwirkung auf “frühere”. Komplexe
SQL-Statements zu schreiben ist eine Kunst, die geübt und beherrscht werden
will. Für den “Hausgebrauch” ist es aber besser, drei einfache Select‑Anweisungen
zu kombinieren als eine große – und falsche – zu verwenden. Subtile, oft
unentdeckt bleibende Fehler in Select-Anweisungen wiegen meist schwerer als ein
eventueller Performancenachteil.